1.4.1 Complexity versus security – features
The following thought experiment illustrates why complexity arising from the number of features or options is a major security risk. Imagine an IT system, say a small web server, whose configuration consists of 30 binary parameters (that is, each parameter has only two possible values, such as on or off). Such a system has more than a billion possible configurations. To guarantee that the system is secure under all configurations, its developers would need to write and run several billion tests: one test for each relevant type of attack (e.g., Denial-of-Service, cross-site scripting, and directory traversal) and each configuration. This is impossible in practice, especially because software changes over time, with new features being added and existing features being refactored. Moreover, real-world IT systems have significantly more than 30 binary parameters. As an example, the NGINX web server has nearly 800 directives for configuring how the NGINX worker processes handle connections.
1.4.2 Complexity versus security – emergent behavior
A related phenomenon that creates security risks in complex systems is the unanticipated emergent behavior. Complex systems tend to have properties that their parts do not have on their own, that is, properties or behaviors that emerge only when the parts interact [186]. Prime examples for security vulnerabilities arising from emergent behavior are time-of-check-to-time-of-use (TOCTOU) attacks exploiting concurrency failures, replay attacks on cryptographic protocols where an attacker reuses an out-of-date message, and side-channel attacks exploiting unintended interplay between micro-architectural features for speculative execution.
1.4.3 Complexity versus security – bugs
Currently available software engineering processes, methods, and tools do not guarantee error-free software. Various studies on software quality indicate that, on average, 1,000 lines of source code contain 30-80 bugs [174]. In rare cases, examples of extensively tested software were reported that contain 0.5-3 bugs per 1,000 lines of code [125].
However, even a rate of 0.5-3 bugs per 1,000 lines of code is far from sufficient for most practical software systems. As an example, the Linux kernel 5.11, released in 2021, has around 30 million lines of code, roughly 14% of which are considered the ”core” part (arch, kernel, and mm directories). Consequently, even with extensive testing and validation, the Linux 5.11 core code alone would contain approximately 2,100-12,600 bugs.
And this is only the operating system core without any applications. As of July 2022, the popular Apache HTTP server consists of about 1.5 million lines of code. So, even assuming the low rate of 0.5-3 bugs per 1,000 lines of code, adding a web server to the core system would account for another 750-4,500 bugs.
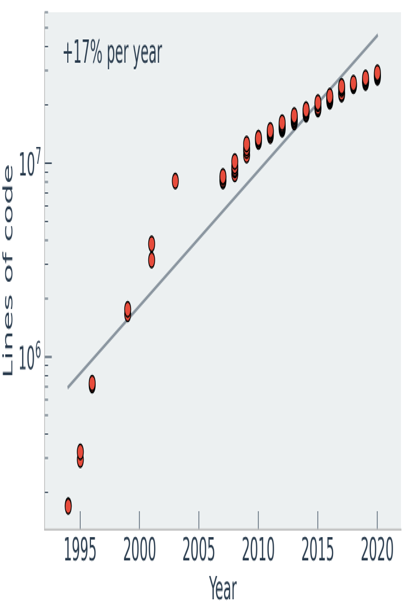
Figure 1.7: Increase of Linux kernel size over the years
What is even more concerning is the rate of bugs doesn’t seem to improve significantly enough over time to cope with the increasing software size. The extensively tested software having 0.5-3 bugs per 1,000 lines of code mentioned above was reported by Myers in 1986 [125]. On the other hand, a study performed by Carnegie Mellon University’s CyLab institute in 2004 identified 0.17 bugs per 1,000 lines of code in the Linux 2.6 kernel, a total of 985 bugs, of which 627 were in critical parts of the kernel. This amounts to slightly more than halving the bug rate at best – over almost 20 years.
Clearly, in that same period of time from 1986 to 2004 the size of typical software has more than doubled. As an example, Linux version 1.0, released in 1994, had about 170,000 lines of code. In comparison, Linux kernel 2.6, which was released in 2003, already had 8.1 million lines of code. This is approximately a 47-fold increase in size within less than a decade.
Figure 1.8: Reported security vulnerabilities per year